
Drugiego dnia konferencji Microsoft Build 2026 została zaprezentowana nowość o nazwie Web IQ. Jest to nowoczesny zestaw "gruntujących" interfejsów API dla sztucznej inteligencji. Rozwiązanie to powstało, aby zasilać aplikacje oraz autonomiczne agenty AI świeżymi, rzetelnymi informacjami pochodzącymi bezpośrednio z publicznej sieci, w tym ze stron internetowych, wiadomości, obrazów czy materiałów wideo.
Koniec ograniczania się agentów do statycznej wiedzy
Tradycyjne duże modele językowe (LLM) są ograniczone czasowo przez moment zakończenia ich treningu. Aby sztuczna inteligencja mogła dostarczać wiarygodne i aktualne odpowiedzi, potrzebuje stałego dostępu do bieżących danych. Microsoft oferował dotychczas funkcję Grounding with Bing Search, zapewniając Copilotowi dostęp do aktualnych danych na długo przed tym, jak analogiczną funkcję wprowadził OpenAI do ChatGPT. Nadejście ery autonomicznych agentów wymusiło jednak istotną zmianę podejścia.
Użyteczność nowoczesnych systemów AI nie zależy już wyłącznie od możliwości samego modelu. Kluczowa staje się efektywność, z jaką cała infrastruktura łączy model z dynamicznie zmieniającym się światem zewnętrznym i z wiedzą, która jest zbyt obszerna, by zakodować ją w pamięci modelu. Systemy definiujące obecną erę muszą błyskawicznie pozyskiwać wiarygodne dowody i przekształcać je w użyteczny kontekst, mieszcząc się przy tym w rygorystycznych budżetach opóźnień i wydajności. Microsoft już wie, jak to ogarnąć.
Web IQ to specjalna wyszukiwarka dla systemów AI
Podczas gdy tradycyjna wyszukiwarka Bing została zaprojektowana z myślą o ludziach, Web IQ powstało jako wyszukiwarka dla systemów AI. Różnica jest zasadnicza: ludzki użytkownik zazwyczaj wpisuje jedno zapytanie, podczas gdy agenty AI działają w wielokrokowych pętlach, wielokrotnie przeszukując sieć, analizując dowody, adaptując się do nowych faktów i wykonując operacje w ułamkach sekund.

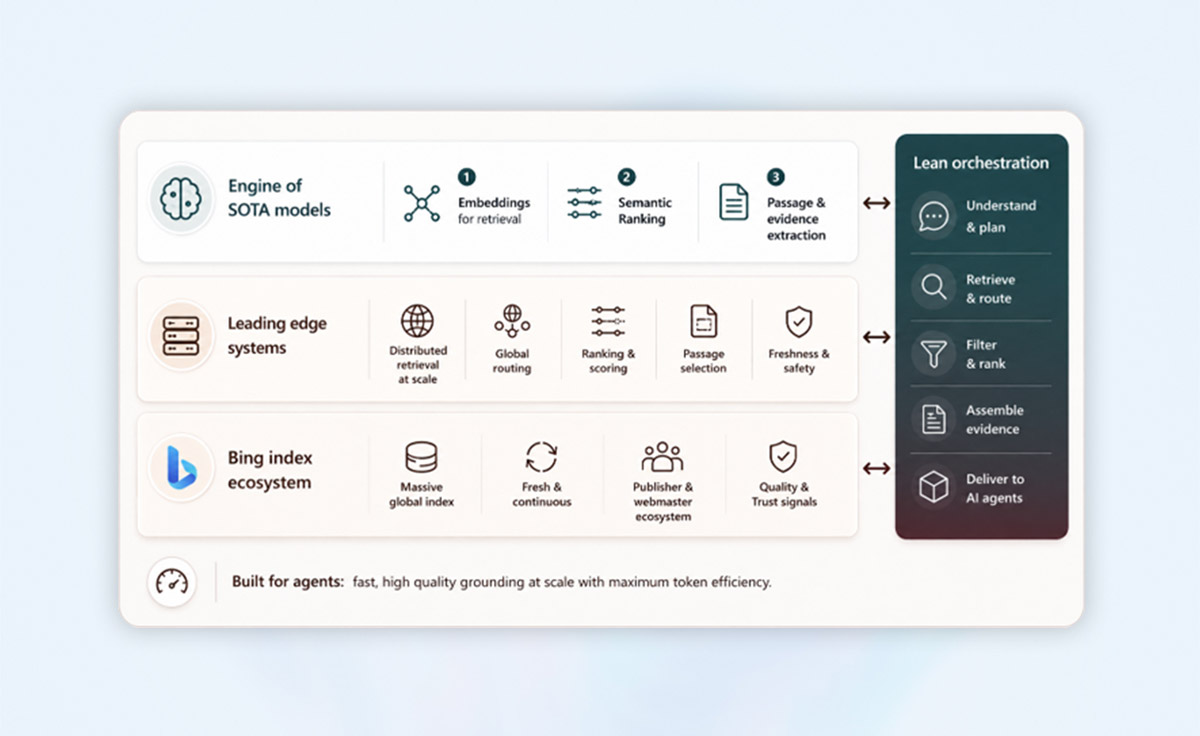
Aby sprostać tym wymaganiom, Microsoft nie ograniczył się do modyfikacji pojedynczych elementów starego systemu. Infrastruktura wyszukiwarki została zaprojektowana całkowicie od podstaw - od procesów indeksowania i wyszukiwania, przez ranking i selekcję fragmentów tekstu, aż po warstwę orkiestracji. Web IQ opiera się na czterech filarach:
- Globalny indeks Bing jako baza: system bazuje na rozwijanym od dekad indeksie wyszukiwarki Bing. Gwarantuje on szeroki zasięg, świeżość i wiarygodność danych. Co ważne, Web IQ w pełni respektuje standardy otwartej sieci, w tym protokoły wykluczania robotów (robots.txt) czy preferencje wydawców dotyczące prywatności i dostępu do treści. Microsoft aktywnie współpracuje z organizacjami takimi jak IETF, aby współtworzyć interoperacyjne standardy dla AI.
- Zintegrowana warstwa modeli: zamiast rozproszonej kolekcji wyspecjalizowanych narzędzi Web IQ opiera się na kilku ściśle zintegrowanych, światowej klasy modelach. Kluczowym elementem jest zaawansowany model zagnieżdżający (ang. embedding model), który precyzyjnie osadza informacje w przestrzeni semantycznej, gwarantując trafianie w odpowiednie "sąsiedztwo" poszukiwanych danych. Towarzyszą mu modele zoptymalizowane pod kątem rozumienia treści i rankingu, których cele są bezpośrednio powiązane z procesami wnioskowania LLM.
- Skalowalne systemy rozproszone i technologia DiskANN: gdy semantyka ustępuje miejsca inżynierii systemowej, Web IQ wykorzystuje architekturę DiskANN. Pozwala ona na przeszukiwanie gigantycznych wektorowych baz danych przechowywanych na dyskach bez poświęcania czasu reakcji i konieczności kosztownego kompromisu między pamięcią a dokładnością wyszukiwania.
- Dostarczanie fragmentów zamiast dokumentów: modele AI nie potrzebują całych dokumentów, lecz konkretnych informacji. Web IQ filtruje dane na poziomie precyzyjnych akapitów i ustrukturyzowanych obiektów dowodowych. Eliminuje to zbędny szum informacyjny i pozwala uzyskać znacznie wyższy stosunek wiedzy do liczby zużytych tokenów, realizując zasadę "mniej tokenów na wejściu - lepsze odpowiedzi na wyjściu - niższy koszt operacyjny".
Nowe standardy wyszukiwania dla agentów AI
Działanie agentów AI w świecie realnym jest determinowane przez trzy powiązane ze sobą parametry, które Web IQ optymalizuje jednocześnie:
- Satysfakcja z ugruntowania wiedzy (GDSAT): zamiast tradycyjnych wskaźników trafności Microsoft mierzy skuteczność za pomocą metryki GDSAT (ang. grounding satisfaction). Ocenia ona stopień, w jakim dostarczone dowody spełniają intencje użytkownika pod kątem kompletności, świeżości i autorytatywności treści. W testach na produkcyjnych zestawach zapytań Web IQ regularnie osiąga wyższe wyniki satysfakcji niż systemy alternatywne.
- Prędkość klasy produkcyjnej: zbyt wysokie opóźnienia uniemożliwiają agentom realizację wielokrokowego wnioskowania. Web IQ działa na poziomie latencji p95 poniżej 165 milisekund. W wewnętrznych benchmarkach przeprowadzonych na unikalnych zapytaniach w 5 globalnych centrach danych (w USA, Europie i Korei Południowej) rozwiązanie to okazało się niemal 2,5-krotnie szybsze od najbliższych konkurencyjnych alternatyw z poprzedniej generacji.
- Oszczędność tokenów: dzięki skupieniu się na gęstości informacji w dostarczanych fragmentach system drastycznie zmniejsza rozmiar kontekstu wymaganego do uzyskania poprawnej odpowiedzi, co bezpośrednio obniża koszty i opóźnienia pojedynczych wywołań API.
Na samym szczycie struktury Web IQ znajduje się warstwa orkiestracji, która interpretuje zapytania, rozsyła je do rozproszonych partycji, łączy wyniki z różnych modalności i przekształca je w gotowy materiał dowodowy. Ponieważ warstwa ta jest bezpośrednią częścią pętli wykonawczej agenta AI, decyduje ona o tym, czy system może pozwolić sobie na głębszą, wieloetapową analizę problemu.
Co dalej? Jak prognozuje Microsoft, przyszłość infrastruktury sztucznej inteligencji będzie należeć do systemów, które potrafią analizować świat dokładnie takim, jakim jest w danym momencie - dynamicznym, zmiennym i stale aktualizowanym. Web IQ stanowi fundament tej zmiany, łącząc prędkość i ekonomię z poszanowaniem zasad otwartej sieci.
