Dziś trudno sobie wyobrazić używanie systemu Windows bez szybkiej wyszukiwarki, pozwalającej znaleźć adekwatne pliki jedynie po fragmencie ich zawartości, np. słów występujących w dokumencie Word. Nie zawsze jednak było to takie proste. Korzenie tych nowoczesnych funkcji wyszukiwania sięgają początku lat 90. Wiele opracowanych wówczas technologii używanych jest do dziś, choć przez te prawie trzy dekady zaliczyło niejedną przemianę. Dziś chcemy Was zabrać w podróż przez kolejne etapy ewolucji systemowej wyszukiwarki — od projektu Cairo, poprzez Windows NT 4.0, 2000, XP, Vista, 7, 8/8.1, aż po współczesny Windows 10. Zobaczmy, jak przez ten czas zmieniało się doświadczenie wyszukiwania!
Cairo (1991-1996)
Na początku lat 90. Microsoft pracował nad projektem o nazwie Cairo. Miał on posłużyć do budowy technologii dla następnej generacji systemu operacyjnego, które zrealizowałyby wizję "informacji na wyciągnięcie ręki" Billa Gatesa. Cairo jako system nigdy się nie ukazał, natomiast porcje jego technologii trafiły do innych produktów. Jedna z nich nosiła nazwę Object File System, później znany jako WinFS. Ideą za nim stojącą było nadanie sensu wszystkim bajtom danych w systemie plików w sposób czytelny dla człowieka i umożliwiający wyszukiwanie. Dane miały zostać zorganizowane jako kolekcja obiektów z właściwościami zgodnymi ze schematem silnego typowania — formą organizacji, w której każde wyrażenie ma ustalony typ.
W tamtych czasach aplikacje nie rozumiały wszystkich typów plików, które były tworzone. Były na przykład pliki .pdf, .html, .jpeg i wiele, wiele innych. Każdy zapisywał do plików we własnym formacie, który był dobrze rozumiany przez jego aplikację i... niczyją inną. Wtedy zdawało to egzamin. Aplikacje Adobe otwierały PDF-y, przeglądarka otwierała dokumenty HTML, a aplikacje do zdjęć — GIF-y i JPEG-i. Gdy pojawiła się usługa indeksowania, była ona zaprojektowana tak, by rozumieć te różne typy plików i czynić zawarte w nich dane wyszukiwalnymi w systemie i wszystkich aplikacjach dla zapewnienia szybkiego i efektywnego dostępu.
Przez kolejne 29 lat usługa ewoluowała do formy, która napędza całą gamę rozwiązań w Windows, a także interfejsy API dla deweloperów oraz ich aplikacje.
Windows NT 4.0 (1996)
Usługa indeksowania (Index Server 2.0) została wprowadzona jako część pakietu opcji dla Internet Information Services (IIS) w Windows NT 4.0, by wykonywać indeksowanie zawartości na stronach serwerów webowych. Pozwalało to użytkownikom wyszukiwać tekst na stronach hostowanych na serwerze IIS. Domyślną lokalizacją tych stron była C:\Inetpub. Był to również jeden z pierwszych folderów, w którym usługa indeksowania poszukiwała zawartości.
W tamtym czasie po raz pierwszy została wprowadzona koncepcja filtrów, umożliwiająca ekstrakcję tekstowej zawartości z różnych typów plików i jej zapisanie w usłudze indeksowania. Filtry były dla aplikacji sposobem rejestrowania się z danym rozszerzeniem pliku, który usługa indeksowania mogła przywołać, by złapać zawartość do umieszczenia w indeksie podczas przetwarzania tego pliku. Owo "przetwarzanie" nazywane jest powszechnie właśnie "indeksowaniem".
Próbowaliście kiedyś otworzyć plik PDF w Notatniku? Wiecie, co oznaczają dane, takie jak te poniżej? A co, jeśli istnieje sposób, by znaleźć PDF z konkretnym tekstem w środku bez potrzeby przeglądania całej kolekcji tych plików w systemie?
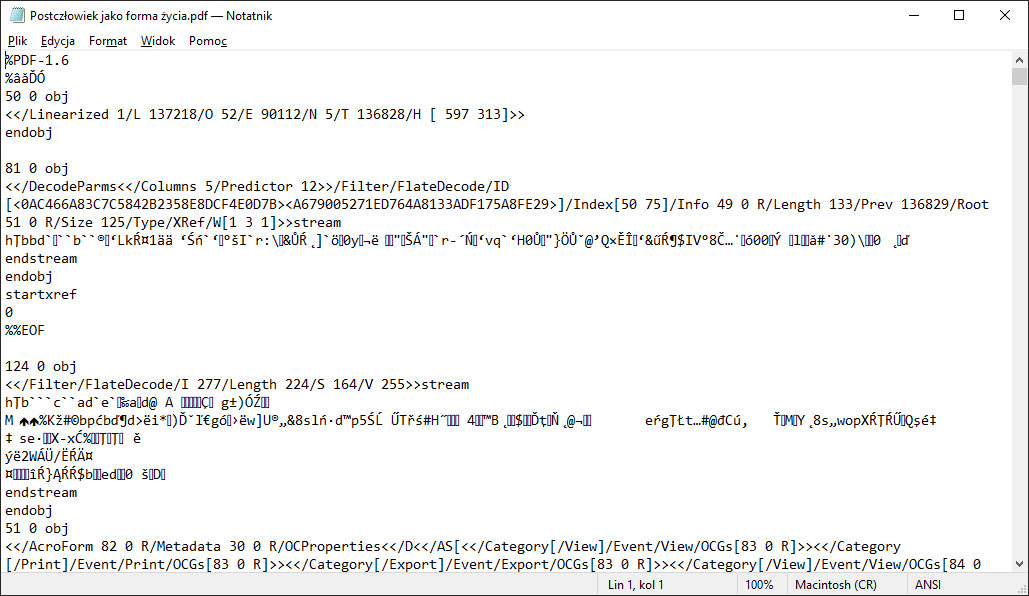
Otwieranie na ślepo plików tego typu nie jest zbyt użytecznym sposobem na przetworzenie tych danych w celu wyszukiwania. To właśnie widziałaby usługa indeksowania, gdyby miała wydobyć z pliku dane bez odpowiedniego filtra. Filtry stały się dla konkretnych typów plików sposobem komunikowania danych cennych z punktu widzenia wyszukiwania. Przykładowo dzięki filtrowi IFilter dla plików .pdf zdania tekstowe, właściwości i metadane z pliku są zwracane i przechowywane w usłudze indeksowania jako mające znaczenie, dające się wyszukiwać dane, które interesują użytkowników.
A w jaki sposób aplikacje czytają indeks? Od początku istniał dostawca usługi indeksowania OLE DB, który zapewniał dostęp tylko do odczytu do treści w indeksie. Używając tego dostawcy, aplikacje mogły korzystać z własnej wersji Structured Query Lanugage (SQL) usługi indeksowania, która była silnie typowanym sposobem pisania kodu, który czyta dane. Wszystkie te API są dziś nadal dostępne do użycia przez deweloperów i aplikacje.
Windows 2000 (2000)
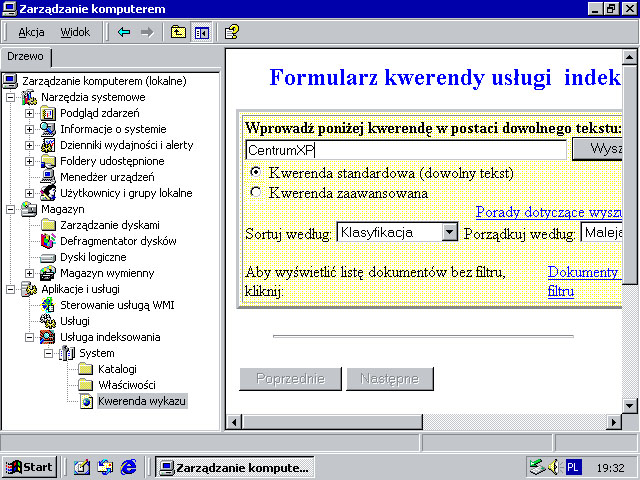
Usługa indeksowania po raz pierwszy stała się częścią systemu w Windows 2000, niemniej jednak była traktowana jako składnik (usługa) Windows, który musiał zostać włączony ręcznie. Po jego włączeniu mogliśmy skonfigurować usługę, by indeksowała strony internetowe hostowane w IIS, tak jak wyglądało to w Windows NT 4.0, oraz foldery lokalne na urządzeniu. Istniały różne miejsca, z których można było rozpocząć wyszukiwanie, takie jak Konsola zarządzania (Microsoft Management Console) czy Eksplorator Windows.
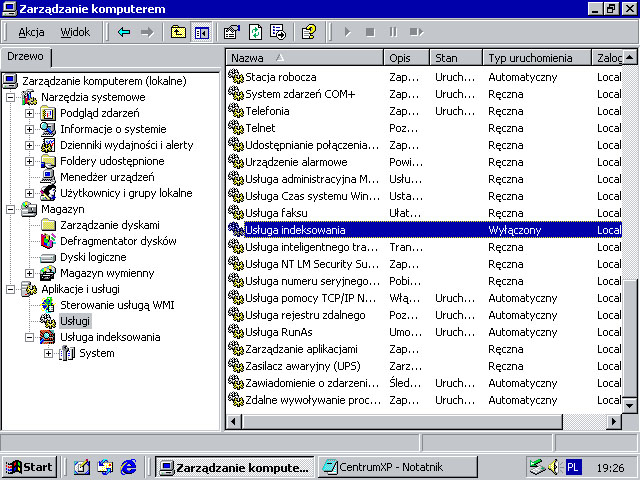
Oprócz wyszukiwania rzeczy usługa pokazywała też użytkownikowi różne statystyki ukazujące, co dzieje się pod przykryciem. Wyświetlały się one w kolumnach w aplikacji Zarządzanie komputerem. Dokumenty do poindeksowania, Opóźnione w celu indeksowania i Listy wyrazów to tylko kilka z nich. Wiele kolejnych było dodawanych w następnych latach i działają one w Windows do dziś.
W Windows 2000 debiutowała też pierwsza wersja USN Journal (Update Sequence Number Journal) jako część NTFS 3.0. Dziennik USN lub też Dziennik zmian to składnik systemu plików, który daje aplikacjom możliwość odczytu wszystkich zmian w każdym woluminie systemu (zakładając, że dzienniki były w nim wspierane) i reagowania na te zmiany. Przetwarzanie tych zmian, aby zrozumieć, kiedy pliki są modyfikowane, by utrzymać indeks możliwie najbardziej aktualnym, jest głównym sposobem, w jaki usługa indeksowania jest powiadamiana o zmianach w pliku/folderze nawet teraz, w Windows 10.
Wspomniane wcześniej filtry IFilters stały się też częściej wybierane przez zewnętrznych producentów, by obsługiwały treści w unikalnych typach plików na użytek ich aplikacji. Popularne filtry w tamtych czasach obsługiwały formaty .pdf, .jpg, .gif, .xml czy .html, by wymienić tylko kilka.
Windows XP (2001)
Gdy z impetem wkroczył na rynek rewolucyjny Windows XP, usługa indeksowania znów była częścią systemu — tym razem włączoną domyślnie. Tak jak w poprzednich wersjach uruchamiała się jako cisvc.exe, będącym skrótem od content indexing service.
Od Windows 2000, poprzez Windows XP usługa indeksowania oddzielała indeksowane przez siebie dane w partycjach bądź katalogach. Katalogi były sposobem trzymania zawartości indeksu w różnych folderach z różnymi ścieżkami. Najpierw systemy te domyślnie obsługiwały katalog System, który przechowywał lokalną zawartość, i Katalog sieciowy, który był tworzony i utrzymywany tylko wówczas, gdy na maszynie włączony był IIS. Katalogi znajdowały się też w różnych obszarach fizycznych dysku, dlatego gdy odinstalowany był IIS, usunięcie katalogu Inetpub prowadziło do usunięcia odpowiedniego katalogu webowego i jego danych.
Wydanie to było też wyjątkowe, jeśli chodziło o rozszerzalność z punktu widzenia deweloperów. Było tworzonych wiele nowych API umożliwiających interakcje z katalogami i konfigurowanie związanych z tym opcji. Jednymi z najczęściej używanych i bardziej rozpoznawanych były ISearchCatalogManager i ISearchCrawlScopeManager.
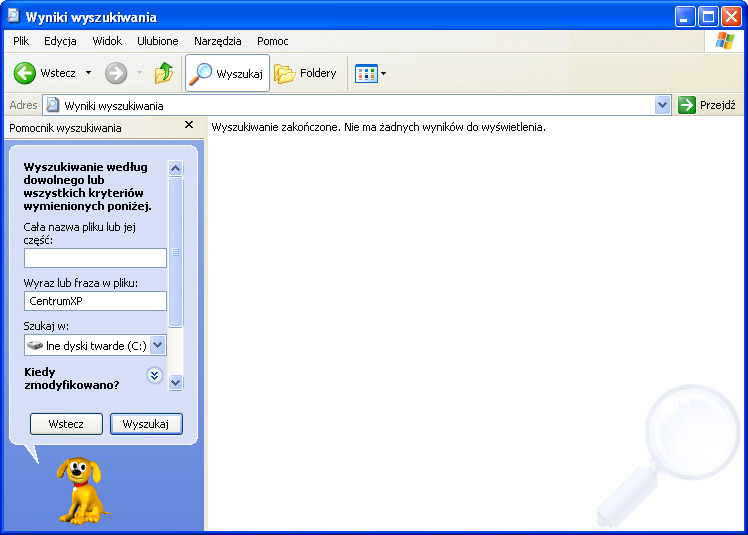
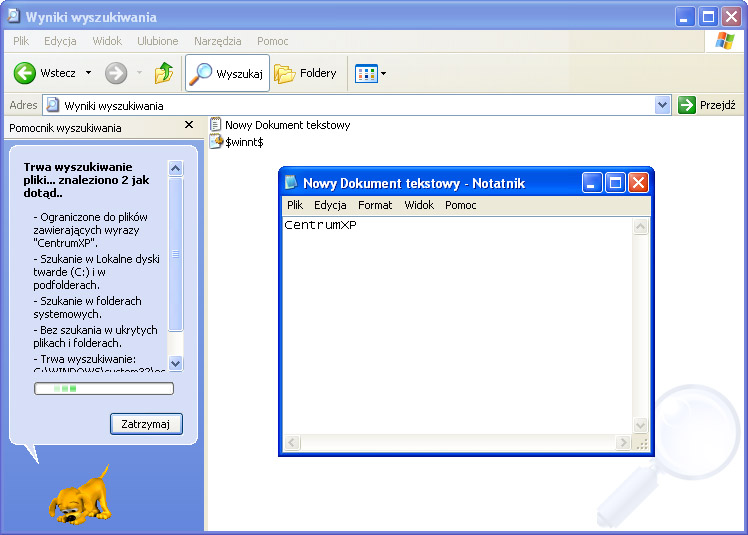
Aplikacje mogły używać API do konfiguracji indeksu, a deweloperzy mogli też dodawać do nich własne typy danych. Pierwotnie usługa indeksowania wiedziała tylko, jak przetwarzać zawartość plików w indeksie, jako że mogła otwierać każdy plik w ten sam sposób (NtCreateFile). Otwieranie e-maili do zindeksowania czy też później innych typów danych Office lub zewnętrznych było czymś wymagającym rozszerzenia i dostępności dla deweloperów. Istniała potrzeba sposobu podłączenia się aplikacji do systemu i dostarczania jej własnych danych, jakiekolwiek by one były. W tamtym czasie deweloperzy zdawali sobie sprawę z tej luki i z tego powodu narodziły się protokoły wyszukiwania.
Aplikacje mogły odtąd tworzyć nowe protokoły wyszukiwania lub różne strumienie zawartości do zaindeksowania, które nie musiały być koniecznie plikami. Protokoły były niezwykle ważną koncepcją, ponieważ ostatecznie dzięki nim indeksowanie Outlook, Visio, SharePoint i innych typów danych stało się możliwe. Wszystko to wywodzi się właśnie z wydania Windows XP i pozostaje aktywne po dziś dzień. Outlook jako jedyny wie, jak przetwarzać e-maile, które ma w swoich plikach .pst/.ost na urządzeniu. Stworzenie interfejsu pozwalającego dostarczać niezbędne dane do indeksowania było kluczowe dla wprowadzania po drodze różnych typów danych.
Windows Vista (2007)
W Windows Vista usługa indeksowania ewoluowała do SearchIndexer.exe i uruchamiała się jako usługa systemowa NT (WSearch). Dodany został nowy panel sterowania do konfiguracji kilku opcji, które stały się bezpośrednio dostępne użytkownikowi. Było to jak kolejne przetarcie szlaków do wyszukiwania, jakie teraz mamy w Windows 10.
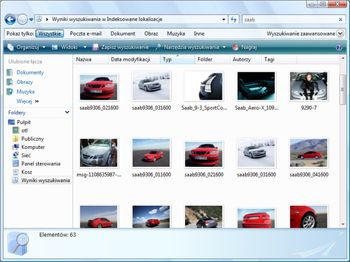
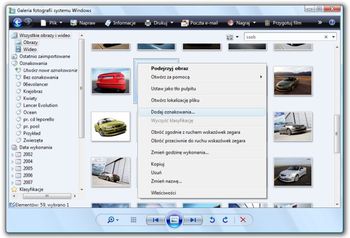
Począwszy od Visty, usługa indeksowania indeksowała wszystkie pliki/foldery w bibliotekach w katalogu profilu użytkownika i uruchamiała się domyślnie przy starcie systemu. Dzięki podejściu Out of the box mogliśmy odnaleźć zapisane w tych lokalizacjach dokumenty bardzo szybko. W tamtym czasie poprawiła się też rozszerzalność, przy czym wspierany był ten sam zestaw API do obsługi zapytań, który został stworzony dla Windows NT 4.0, dzięki czemu aplikacje nadal pracowały tak samo, jak zawsze.
Windows 7 (2009)
Większość funkcji indeksowania z Visty trafiła prosto do Siódemki. Usługa indeksowania domyślnie indeksowała wszystkie pliki i foldery podlegające profilowi użytkownika, jednakże nie indeksowała zawartości wszystkich plików na urządzeniu. To dopiero musiało zostać włączone przez użytkownika. Do Panelu sterowania zawitało nowe ustawienie: Zmień opcje wyszukiwania plików i folderów. Pozwoliło ono wybrać, jakie dane mają być wyszukiwane.
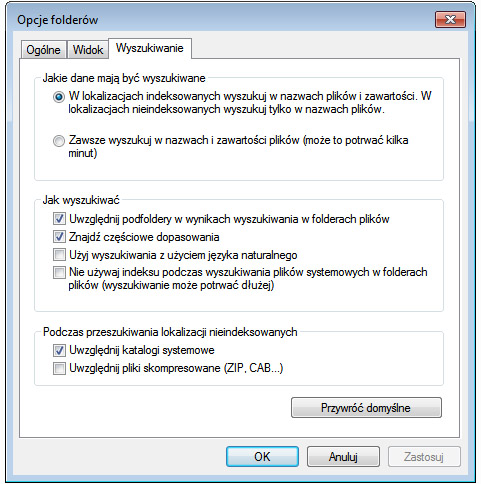
Po włączeniu ustawienia Zawsze wyszukuj w nazwach i zawartości plików (może to potrwać kilka minut) w Opcjach folderów trzeba było poczekać nieco dłużej na ponowne indeksowanie zawartości wszystkich plików przechowywanej obecnie przez usługę. Następnie mogliśmy zacząć wyszukiwanie w menu Start i na pasku wyszukiwania Eksploratora plików, wpisując tylko kilka słów zawartych w tych plikach. Odnalezione frazy były podświetlane w wynikach wyszukiwania, co ułatwiało określenie właściwego pliku.
Windows 8/8.1 (2012)
W przeciwieństwie do poprzednika Windows 8 został wydany z włączonym domyślnie indeksowaniem zawartości wszystkich plików. Wyszukiwanie było niezwykle proste. Wystarczyło zacząć pisać na ekranie Start i skorzystać z filtrów, takich jak Wszędzie, Aplikacje, Ustawienia i Pliki. W ten sposób mogliśmy przeszukiwać jedynie zasoby dysku twardego lub podłączonych do komputera nośników pamięci. Po raz pierwszy w historii "Okienek" wyszukiwanie w sieci mogliśmy rozpocząć już z poziomu ekranu Start, nie klikając nawet żadnej z opcji. By wyszukiwać także w Internecie, należało w ustawieniach wyszukiwania włączyć wyszukiwanie z pomocą Bing.
Wyszukiwanie w systemie Windows 8.1 zostało wzbogacone o kontrolę rodzicielską dla wyników z Internetu. Do wyboru mieliśmy filtrowanie ścisłe - cenzuruje obrazy, filmy i teksty przeznaczone dla dorosłych, średnie - filtruje jedynie obrazy i wideo, pozostawiając treści, lub wyłączone. Dodatkowe opcje pozwalały wyłączyć wyszukiwanie w Bing podczas korzystania z połączeń taryfowych.
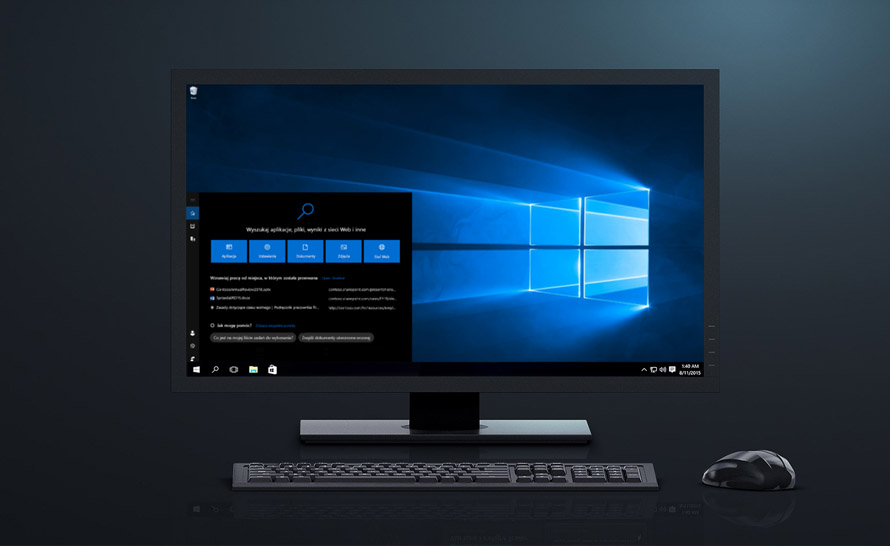
Windows 10 (2015)
Windows 10 zawiera najnowszą wersję indeksatora wyszukiwania z dodanym wsparciem dla uruchamiania się na wielu różnych typach urządzeń. Dodano też nową stronę ustawień w aplikacji Ustawienia, która oferuje niedostępne wcześniej opcje indeksatora.
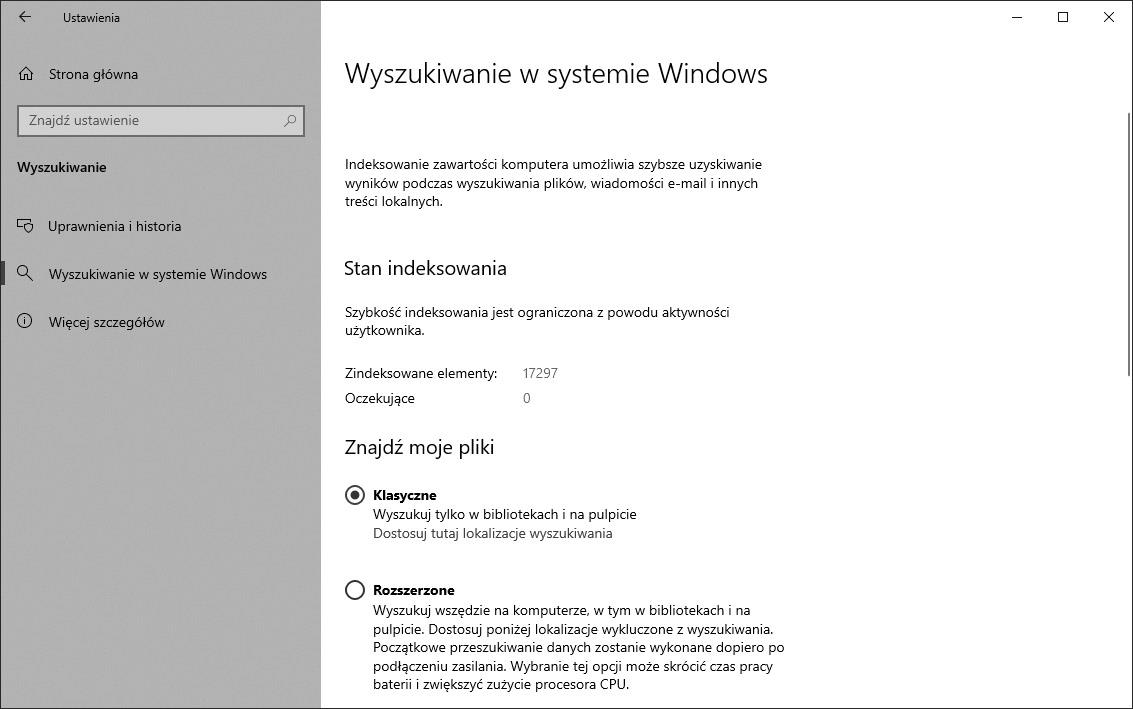
Wśród tych ustawień znalazły się Foldery wykluczone. Jest to lista folderów (możemy dodawać kolejne i usuwać istniejące), których zawartość nie będzie indeksowana. Wykluczenie dużych i nieistotnych z punktu widzenia wyszukiwania folderów poprawia też wydajność systemu, a indeksowanie zabiera mniej miejsca na dysku.
Kluczowe jest także ustawienie Znajdź moje pliki > Rozszerzone, które włącza przeszukiwanie na innych dyskach i folderach poza katalogiem użytkownika. Pliki te można wyszukiwać po nazwie lub podstawowych właściwościach, jednak już nie po zawartości.
W toku rozwoju Windows 10 jego wyszukiwarka została połączona z Microsoft Search, inteligentnym doświadczeniem wyszukiwania dla firm, które wykorzystuje technologię sztucznej inteligencji (AI) od Bing oraz głębokie, spersonalizowane wglądy wyłonione przez Microsoft Graph. Microsoft Search obecny jest dosłownie wszędzie, gdzie się w ekosystemie Microsoft 365 udamy, a więc m.in. w Office, Outlook, SharePoint, OneDrive, Bing i Windows.
Podsumowanie
Mimo iż Cairo i WinFS ostatecznie nie zostały wydane, elementy ich technologii związane z indeksowaniem zawartości nadal są aktywne i używane w wielu produktach Microsoftu, także poza systemami Windows. Ich kod był na przestrzeni lat poprawiany przez liczne zespoły i dostosowywany do kolejnych wersji systemu, niemniej jednak wciąż dzieli podstawowy zestaw interfejsów, których deweloperzy używają do dzisiaj.
