
Żyjemy w czasach, gdy możemy wydać asystentowi AI dowolne polecenie. Rzecz w tym, że wielu z nich on nie wykona, bo jego zasób możliwości jest ograniczony i ma specjalne filtry, które blokują złośliwe, szkodliwe, krzywdzące czy nieodpowiednie działania. Bywały jednak przykłady promptów, które wyprowadzały sztuczną inteligencję w pole. Microsoft wyjaśnia, jakie wprowadza środki bezpieczeństwa, aby temu zapobiegać.
Exploitowanie systemów informatycznych jest tak stare, jak same te systemy, i generatywna sztuczna inteligencja nie jest wyjątkiem. Przeciwnie, tak zachwycające systemy oparte na dużych modelach językowych (LLMs) pokroju GPT-4 stanowią łakomy kąsek dla osób o niecnych zamiarach. W przeciwieństwie do prostych narzędzi aplikacje AI są mocno kontrolowane. Mimo licznych przykładów ułomności aplikacje, takie jak ChatGPT czy Microsoft Copilot, dość sprawnie ukrócają próby nadużyć. W jaki sposób to działa?
Jedną z głównych obaw związanych z AI jest potencjał nadużyć w złośliwych celach. Aby temu zapobiegać, systemy AI w Microsoft są budowane z szeregiem warstw ochrony w całej architekturze. Jednym z celów tych zabezpieczeń jest ograniczenie tego, co LLM robi, aby uzyskać zgodność z ludzkimi wartościami i celami deweloperów. Czasem jednak osoby o złych zamiarach [bad actors] próbują ominąć te środki ochrony z intencją uzyskania nieautoryzowanych działań, które mogą skutkować czymś, co nazywa się "jailbreak". Konsekwencje mogą być różne: od niedozwolonych, ale mniej szkodliwych – jak skłonienie interfejsu AI, aby mówił jak pirat – do bardzo poważnych, jak skłonienie AI do dostarczenia szczegółowych instrukcji, jak uzyskać nielegalne aktywności. W rezultacie sporo wysiłku wkładane jest we wzmacnianie zabezpieczeń przed jailbreakiem, by chronić aplikacje zintegrowane z AI przed takimi zachowaniami.
Podczas gdy aplikacje zintegrowane z AI mogą być atakowane jak tradycyjne oprogramowanie (z metodami takimi jak przepełnienie bufora i cross-site scripting), mogą być też podatne na bardziej wyspecjalizowane ataki, które exploitują ich unikalne cechy charakterystyczne, wliczając w to manipulację lub wstrzyknięcie złośliwych instrukcji, mówiąc do modelu AI poprzez prompt użytkownika. Możemy podzielić te ryzyka na dwie grupy technik ataków:
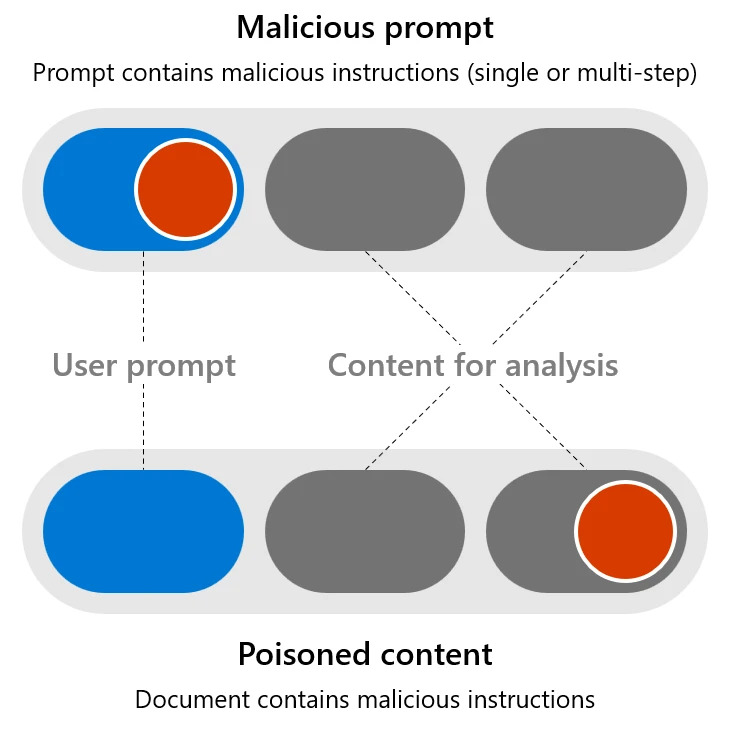
- Złośliwe prompty: Kiedy dane wejściowe użytkownika próbują ominąć systemy bezpieczeństwa, aby osiągnąć niebezpieczny cel. Nazywany także atakiem użytkownika/bezpośredniego wstrzyknięcia lub UPIA.
- Zatruta zawartość: Kiedy użytkownik z dobrymi intencjami prosi system AI, aby przetworzył z pozoru nieszkodliwy dokument (np. podsumował wiadomość e-mail), który zawiera treści stworzone przez złośliwego autora zewnętrznego z celem exploitowania podatności w systemie AI. Nazywany też cross/niebezpośrednim atakiem wstrzyknięcia promptu lub XPIA.
— Mark Russinovich, Chief Technology Officer w Microsoft Azure
Eksperci z Microsoft opracowali szereg technik, wykorzystywanych teraz w produktach, takich jak Copilot:
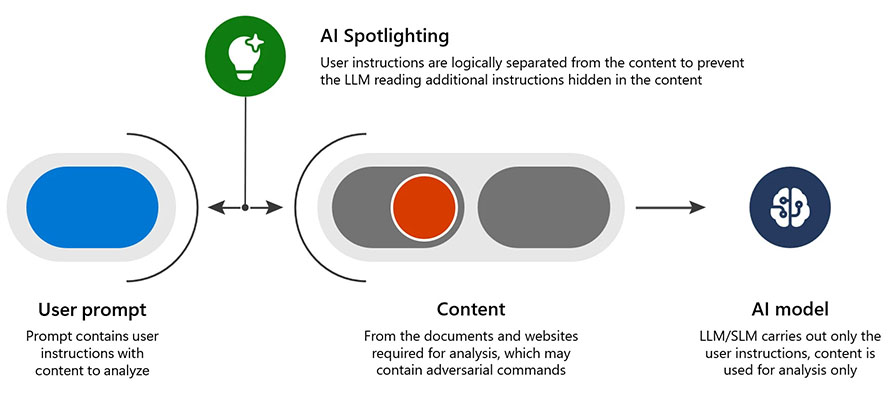
- Spotlighting (znana też jako oznaczanie danych): to technika zmniejszająca wskaźnik powodzenia ataków z wykorzystaniem zatrutej zawartości z ponad 20% do poniżej progu wykrywania z minimalnym wpływem na ogólną wydajność AI. Polega ona na wyraźnym oddzieleniu danych zewnętrznych od instrukcji przez LLM z różnymi metodami oznaczania.
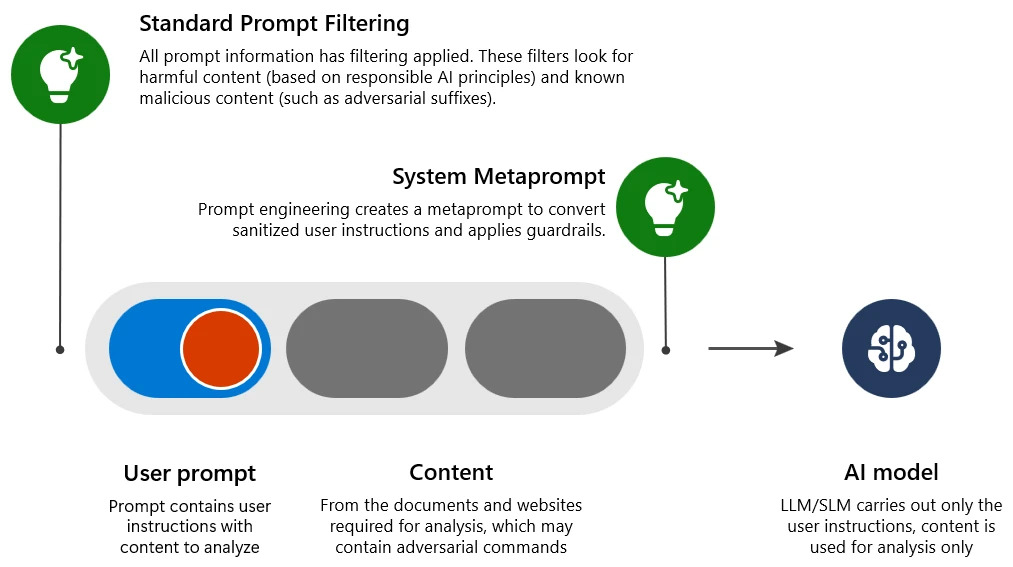
- Standardowe filtrowanie promptów: wykrywa i odrzuca dane wejściowe zawierające szkodliwą lub złośliwą intencję, które mogłyby ominąć środki bezpieczeństwa (powodując atak jailbreak).
- Metaprompt systemu: inżynieria promptów w systemie, która czytelnie wyjaśnia modelowi LLM, jak się zachowywać, oraz zapewnia dodatkowe zabezpieczenia.
- Wielokolejkowy filtr promptów (Multiturn prompt filter): filtry wejściowe patrzą na cały wzór dotychczasowej konwersacji, nie tylko na natychmiastową interakcję. Microsoft odkrył, że samo przekazanie tego większego okna kontekstowego istniejącym detektorom złośliwych zamiarów bez żadnego ulepszania tych detektorów znacznie zmniejszyło skuteczność Crescendo (ataków jailbreak korzystających z wielu kolejek czatu).
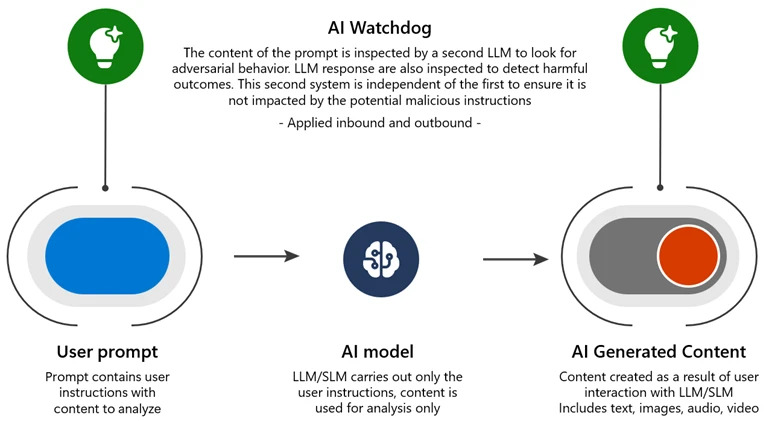
- AI Watchdog: system wykrywania AI wytrenowany na przykładach, który przypomina psa tropiącego na lotnisku, szukającego przemycanych przedmiotów w bagażu. Jako odrębny system AI unika wpływu złośliwych instrukcji. Przykładem takiego podejścia jest Microsoft Azure AI Content Safety.
- Zaawansowane badania: Microsoft inwestuje w badania nad bardziej złożonymi środkami zapobiegawczymi, wynikającymi z lepszego zrozumienia, w jaki sposób LLM przetwarza żądania i schodzi na manowce. Mają one potencjał do ochrony nie tylko przed Crescendo, ale także przed większą rodziną ataków socjotechnicznych na LLM.
Wydaje się, że twórcy odpowiedzialnej AI są zawsze o krok przed cyberprzestępcami, a dotychczasowe próby nadużyć nie poskutkowały niczym szczególnie groźnym. Nie wiadomo, jak długo taki stan potrwa, ani jak wpłynie na niego opracowanie sztucznej inteligencji ogólnego zastosowania (AGI), nad którą otwarcie pracują OpenAI, Microsoft i inni giganci technologiczni. Nie jesteśmy jednak czarnowidzami. Dotychczasowe zasady i środki bezpieczeństwa, implementowane przez czołowych twórców AI u samych jej podstaw, świadczą o dużej odpowiedzialności, a także zdolności przewidywania przyszłych wydarzeń i możliwych scenariuszy nadużyć.
