Systemy wizualno-językowe (vision-language, VL) pozwalają wyszukiwać adekwatne obrazy dla zapytań tekstowych (i vice versa) oraz opisywać zawartość obrazu naturalnym językiem. Systemy takie używają modułu odkodowywania obrazu i modułu fuzji wizualno-językowej. Microsoft Research opracował niedawno nowy system rozpoznawania atrybutów obiektów dla odkodowywania obrazów o nazwie VinVL (Visual features in Vision-Language). W grupie topowych benchmarków osiągnął wyniki lepsze od ludzkich.
Ludzkie rozumienie świata opiera się na fuzji informacji z różnych kanałów, takich jak wzrok, słuch i inne zmysły. Jedną z kluczowych aspiracji twórców AI jest rozwinięcie algorytmów, które wyposażą komputery w podobną możliwość: efektywnego uczenia się z multimodalnych danych, aby zrozumieć świat dookoła. Przykładem takiego działania są właśnie systemy wizualno-językowe.
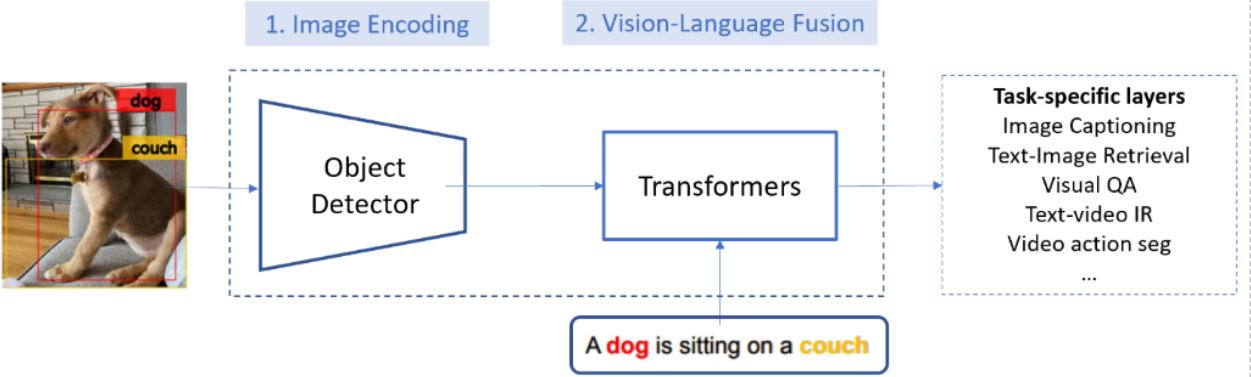
Jak informuje Microsoft Research, wstępne szkolenie systemów vision-language (VLP) zaliczyło ostatnimi czasy duże postępy dzięki działaniu na dużą skalę, niemniej jednak istniejące metody VLP napotykały na pewne opory. Odpowiedzią na nie są innowacje zaprowadzone przez VinVL:
Łącząc VinVL z najwyższej jakości modułami fuzji VL, takimi jak OSCAR i VIVO, system Microsoft VL wyznaczył nowy rekord we wszystkich siedmiu głównych benchmarkach VL, osiągając pierwsze miejsce w najbardziej konkurencyjnych rankingach, wliczając w to Visual Question Answering (VQA), Microsoft COCO Image Captioning i Novel Object Captioning (nocaps). Co szczególnie ważne, system Microsoft VL znacząco przewyższył wydajność ludzką w rankingu nocaps, na polu CIDEr (92.5 vs. 85.3).
— Pengchuan Zhang, Lei Zhang, Jianfeng Gao, Microsoft Research

Microsoft zapowiada, że udostępni publicznie model VinVL wraz z jego kodem źródłowym. Więcej informacji można zasięgnąć w artykule i repozytorium GitHub. VinVL jest ponadto integrowany z Azure Cognitive Services, zasilając wiele multimodalnych scenariuszów, takich jak Seeing AI czy podpisy dla obrazów w Office i LinkedIn. Jest on także częścią inicjatywy AI at Scale.
