
Microsoft ogłosił znaczący krok naprzód w rozwoju swojego agenta AI do głębokiego researchu w ramach Microsoft 365 Copilot. Researcher otrzymał dwie innowacyjne, wielomodelowe funkcjonalności – Critique oraz Council – które podnoszą poprzeczkę w zakresie dokładności, głębi i wiarygodności generowanych raportów. Powstały one, by wspierać użytkowników w wykonywaniu najbardziej złożonych zadań badawczych bezpośrednio w toku codziennej pracy, wykorzystując potencjał wiodących modeli AI od zewnętrznych partnerów, takich jak OpenAI i Anthropic. Obie nowości są już dostępne poprzez program Frontier.
Critique: Dwustopniowa kontrola jakości
Critique w Researcherze odchodzi od tradycyjnego podejścia, w którym pojedynczy model AI odpowiada za cały proces od planowania po pisanie. Zamiast tego rozdziela zadania między dwóch "partnerów AI", generatora i recenzenta. Ten pierwszy odpowiada za fazę eksploracji, planowanie zadania, iteracyjne wyszukiwanie informacji i przygotowanie wstępnego szkicu. Drugi zaś skupia się wyłącznie na ocenie i udoskonaleniu treści. Pełni rolę eksperta, który sprawdza raport przed jego sfinalizowaniem, ale nie staje się jego współautorem.
Proces ten opiera się na ustrukturyzowanej rubryce ocen, która kładzie nacisk na trzy kluczowe aspekty:
- Wiarygodność źródeł: priorytetyzacja sprawdzalnych i autorytatywnych dowodów.
- Kompletność raportu: weryfikacja, czy odpowiedź w pełni wyczerpuje intencje użytkownika.
- Rygorystyczne ugruntowanie w faktach: wymóg, aby każde kluczowe twierdzenie było poparte precyzyjnym cytatem.
Skuteczność architektury Critique została poddana rygorystycznym testom na benchmarku DRACO (Deep Research Accuracy, Completeness, and Objectivity), obejmującym 100 złożonych zadań z 10 różnych dziedzin (m.in. medycyny, prawa i technologii). Do oceny wyników wykorzystano model GPT-5.2 jako najbardziej surowego "sędziego". Wyniki pokazały wyraźną przewagę modelu dwuskładnikowego nad tradycyjnym, opartym na jednym modelu Researcherze.
- Głębia i szerokość analizy: wzrosły o +3,33 pkt.
- Jakość prezentacji: wzrosła o +3,04 pkt.
- Dokładność faktyczna: wzrosła o +2,58 pkt.
Analizy statystyczne potwierdziły poprawę w 8 z 10 badanych dziedzin, co dowodzi, że Critique działa skutecznie jako uniwersalna warstwa podnosząca jakość, pomagając identyfikować luki w analizie i zaostrzać precyzję twierdzeń.
Council: zestawienie wielu perspektyw
Drugą nowością jest Council, który umożliwia zestawienie odpowiedzi z różnych modeli (Anthropic i OpenAI) obok siebie. Każdy z modeli tworzy niezależny raport, co pozwala na wyłapanie faktów lub interpretacji, które drugi model mógłby pominąć. Unikalnym elementem Council jest list przewodni generowany przez dedykowany model sędziowski. Dokument ten analizuje oba raporty i wskazuje użytkownikowi:
- Punkty wspólne, w których modele są zgodne.
- Rozbieżności w interpretacji lub skali zjawisk.
- Unikalne spostrzeżenia wniesione przez każdą ze stron.

Dostępność
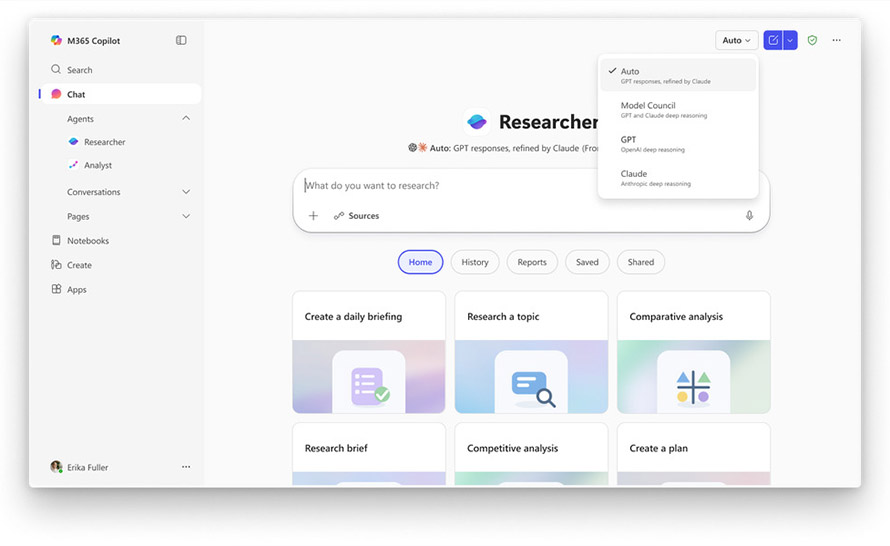
Critique oraz Council są już szeroko dostępne dla użytkowników z licencją Microsoft 365 Copilot, należących do programu Frontier. Critique stanie się domyślnym doświadczeniem Researchera po wybraniu opcji "Auto" w selektorze modeli, natomiast Council można aktywować, wybierając opcję "Model Council".
Dowiedz się więcej z naszych artykułów:
