OpenAI ogłosił wprowadzenie trzech przełomowych modeli audio przeznaczonych dla deweloperów budujących aplikacje oraz dla agentów głosowych. Nowa linia produktów obejmująca modele GPT-Realtime-2, GPT-Realtime-Translate oraz GPT-Realtime-Whisper, ma na celu wyeliminowanie barier w naturalnej komunikacji między człowiekiem a maszyną, oferując niespotykaną dotąd szybkość, inteligencję i wielojęzyczność.
Wprowadzamy poprzez API trzy modele dźwiękowe, które odblokowują nową klasę aplikacji głosowych dla deweloperów. Z tymi modelami deweloperzy mogą budować doświadczenia głosowe, które odczuwane są jako bardziej naturalne, odpowiadają inteligentniej i podejmują działania w czasie rzeczywistym - czytamy w oficjalnym oświadczeniu OpenAI.
GPT-Realtime-2 - nowy lider wśród modeli audio
Flagowym modelem nowej serii jest GPT-Realtime-2, pierwszy model głosowy oferujący rozumowanie klasy GPT-5. Został on zaprojektowany do obsługi złożonych interakcji na żywo, w których agent AI musi nie tylko słuchać, ale także aktywnie działać i korygować błędy w trakcie rozmowy. Model ten wprowadza szereg funkcji kluczowych dla profesjonalnych wdrożeń:
- Preambuły: możliwość wypowiadania krótkich fraz typu "pozwól mi to sprawdzić" przed wykonaniem zadania, co poprawia naturalność przepływu rozmowy.
- Równoległe wywołania narzędzi: agent może korzystać z wielu narzędzi jednocześnie, informując o tym użytkownika na bieżąco.
- Lepsza regeneracja: model raczej "milczy" w obliczu błędu, potrafiąc zakomunikować trudność w sposób płynny.
- Rozszerzony kontekst: okno kontekstowe zostało zwiększone z 32K do 128K tokenów.
- Kontrola tonu i rozumowanie: programiści mogą teraz wybierać poziom wysiłku rozumowania (minimal, low, medium, high, xhigh) oraz kontrolować styl mówienia (np. spokojny lub empatyczny).
- Lepsze zrozumienie danej dziedziny: model obsługuje specjalistyczną terminologię, nazwy własne, terminy z zakresu opieki zdrowotnej i inne słownictwo, które ma znaczenie w środowiskach produkcyjnych.
Skok jakościowy potwierdzają twarde dane. GPT-Realtime-2 w wersji high reasoning uzyskał wynik 96,6% w benchmarku Big Bench Audio, deklasując model GPT-Realtime-1.5, który osiągnął 81,4%. Z kolei w teście podążania za instrukcjami Audio MultiChallenge najwyższa wersja xhigh zdobyła 48,5% punktów (wobec 34,7% poprzednika).
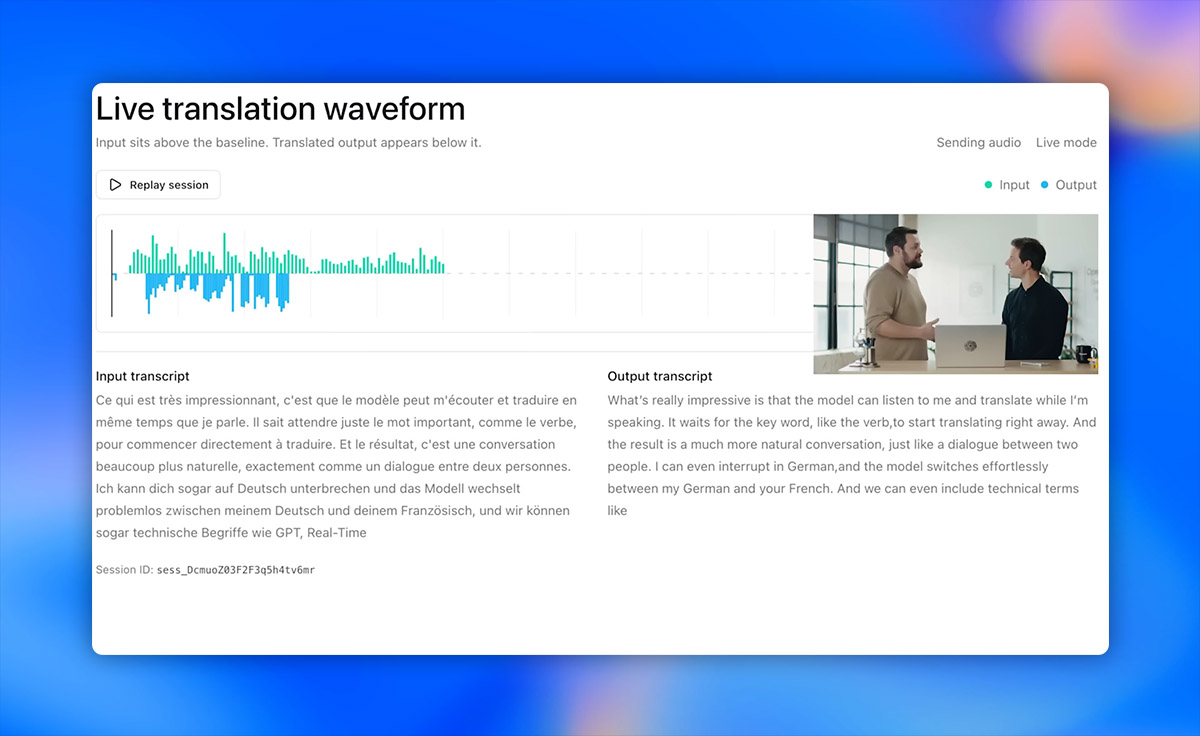
Tłumaczenie i transkrypcja w czasie rzeczywistym
Dwa pozostałe modele adresują konkretne potrzeby komunikacyjne:
- GPT-Realtime-Translate: model dedykowany do wielojęzycznych doświadczeń głosowych. Obsługuje ponad 70 języków wejściowych i 13 języków wyjściowych. Według OpenAI pozwala on na zachowanie sensu wypowiedzi nawet przy zmianach kontekstu czy używaniu dialektów regionalnych.
- GPT-Realtime-Whisper: model do streamingu transkrypcji o niskiej latencji. Jest idealnym rozwiązaniem do generowania napisów na żywo, notatek z lekcji czy spotkań biznesowych w trakcie ich trwania.
Nowości od OpenAI już dostępne poprzez API
Nowości te mogą sprawdzić się w aplikacjach napędzanych przez AI opartych na modelach Voice-to-action, Systems-to-voice oraz Voice-to-voice. Wszystkie wymienione nowości są już dostępne w Realtime API. Koszty użytkowania prezentują się następująco:
- GPT-Realtime-2: 32 USD za 1M tokenów wejściowych audio (0,40 USD za tokeny zbuforowane) oraz 64 USD za 1M tokenów wyjściowych audio.
- GPT-Realtime-Translate: 0,034 USD za minutę działania.
- GPT-Realtime-Whisper: 0,017 USD za minutę działania.
