GitHub, który jest fundamentem współczesnego rozwoju oprogramowania, mierzy się z bezprecedensowymi wyzwaniami technicznymi. Gwałtowny rozwój narzędzi oraz autonomicznych agentów AI doprowadził do wzrostu obciążenia, którego skala zaskoczyła nawet samych wydawców platformy należącej do Microsoftu. Choć jeszcze w październiku 2025 r. planowano zwiększenie wydajności 10-krotnie, zaledwie kilka miesięcy później rzeczywistość zweryfikowała te założenia. Co się zmieniło?
Deweloperzy na potęgę korzystają z narzędzi sztucznej inteligencji i tzw. agentów kodowania. Automatyzacja pracy spowodowała duży wzrost użycia serwerów GitHub, które ledwo wyrabiają z przetwarzaniem tego wszystkiego. Bieżącą sytuację i planowaną odpowiedź nakreślił Vlad Fedorov, Chief Technology Officer w GitHub. Zaczęliśmy wdrażać nasz plan zwiększenia wydajności 10-krotnie w październiku 2025 z celem zrównoważonej poprawy niezawodności i odporności na awarie. W lutym 2026 stało się jasne, że powinniśmy byli projektować z myślą o przyszłości, która wymaga 30-krotności dzisiejszej skali - wyjaśnił ekspert.
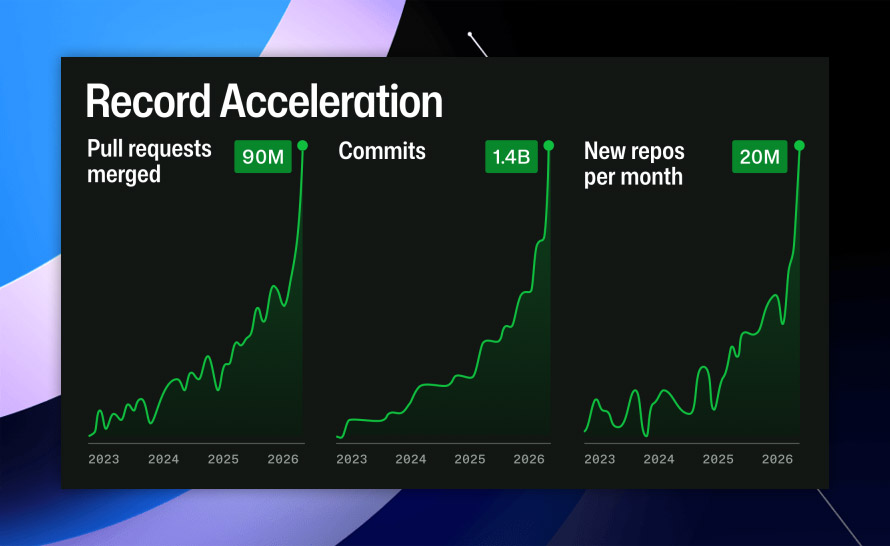
Głównym motorem napędowym tych zmian jest przejście na tzw. agentic development, czyli na model pracy, w którym dużą część zadań wykonują autonomiczne agenty AI. Od połowy grudnia 2025 r. proces ten gwałtownie przyspieszył, co widać w statystykach: liczba merge'owanych pull requestów sięgnęła 90 milionów, commitów - 1,4 miliarda, a miesięcznie powstaje nawet 20 milionów nowych repozytoriów.
Taka skala nie obciąża pojedynczego elementu, lecz cały ekosystem usług. W obliczu tych trudności GitHub ustalił twardą hierarchię priorytetów: na pierwszym miejscu znalazła się dostępność, następnie przepustowość, a dopiero na końcu nowe funkcje.
Aby opanować sytuację, inżynierowie z GitHub podjęli szereg działań krótko- i długoterminowych. Wykorzystano zasoby chmury Azure do zwiększenia mocy obliczeniowej oraz rozpoczęto izolowanie krytycznych usług, takich jak Git i GitHub Actions, od reszty obciążeń. Przepisano również część kodu z monolitu Ruby na język Go oraz przeniesiono zasoby do architektury multi-cloud, by zapewnić większą elastyczność i odporność na awarie.
Mimo podjętych działań ostatnie dni przyniosły dwie poważne awarie, które odbiły się szerokim echem w społeczności (m.in. doprowadzając do deklaracji Mitchella Hashimoto o przeniesieniu projektu Ghostly poza GitHub):
- Incydent z 23 kwietnia: błąd spowodował regresję w operacjach kolejkowania zmian. Awaria dotknęła 658 repozytoriów i 2092 pull requestów, prowadząc do nieumyślnego cofnięcia niektórych zmian w głównych gałęziach projektów.
- Incydent z 27 kwietnia: przeciążenie podsystemu wyszukiwania (prawdopodobnie przez atak botnetu) sparaliżowało część interfejsu użytkownika. Choć nie doszło do utraty danych, brak wyników wyszukiwania w pull requestach i issues znacząco utrudnił pracę deweloperom.
GitHub deklaruje, że wyciąga wnioski z tych porażek. Firma zaktualizowała swoją stronę statusu platformy, aby uwzględniała szczegółowe dane o dostępności, a także zobowiązała się do raportowania nawet mniejszych incydentów.
Co się zmienia w infrastrukturze GitHub? Nasze priorytety redukujemy zbędną pracę, poprawiamy caching, izolujemy krytyczne usługi, usuwamy pojedyncze punkty awarii i przenosimy wrażliwe pod kątem wydajności ścieżki do systemów zaprojektowanych dla tych obciążeń - tłumaczy Fedorov.
