
Większość serwisów gromadzących i operujących na danych korzysta z mniejszych lub większych serwerów baz danych. Wśród tych serwerów zdecydowana większość działa w oparciu o relacyjną strukturę danych. Tematowi relacyjnych baz danych i sposobu organizacji danych chciałbym poświęcić poniższe parę stron.
Model relacyjnych baz danych został formalnie przedstawiony
w latach siedemdziesiątych. Od tamtego czasu na ten temat zostało wydanych
setki książek i tysiące czasopism. Wszystko to sprawiło, że z początkowej
prostej zasady powstała rygorystycznie zdefiniowana koncepcja gromadzenia i
przetwarzania danych.
Model relacyjnych baz danych reprezentowany jest za pomocą dwuwymiarowych
tablic. Każda z tablic reprezentuje obiekty z rzeczywistego świata: ludzi,
miejsca, ceny lub zdarzenia, o których chcemy zbierać informacje. Sama
relacyjna baza danych jest zbiorem takich dwuwymiarowych tablic opisujących
rzeczywistość. W ten sposób baza danych prezentuje dane użytkownikom lub
programistom.
Sposób, w jaki baza danych - w naszym przypadku MS SQL Server 2005 -
przechowuje dane na fizycznych dyskach nie będzie poruszany w tych artykułach.
Podstawowe zrozumienie mechanizmów funkcjonowania relacyjnego modelu danych
jest niezbędne do efektywnego używania systemów bazodanowych takich jak SQL
Server 2000/2005 czy Oracle, jak również małych systemów, takich jak
MS Access, które również bazują na relacyjnej organizacji danych.
Artykuły te są jedynie wstępem do relacyjnej koncepcji danych, skupimy się w
nich na tych aspektach, dzięki którym w szybkim czasie będziemy mogli
skutecznie projektować i administrować serwerem bazy danych. Pominiemy zaś
matematyczne teorie związane z relacjami.
Struktura i terminologia
Jak wspomniałem wcześniej, w relacyjnym modelu baza danych jest kolekcją powiązanych ze sobą tabel. Tabela jest płaską strukturą zawierającą z góry określoną liczbę kolumn i dowolną liczbę wierszy. Kolumny charakteryzują samą tabelę i dane, jakie mogą się w niej znajdować. Wiersze zaś mówią już o obiekcie (osobie, samochodzie itd.), o którym dane chcemy gromadzić. Każda z kolumn posiada kategorię danych, które mogą się pojawić w tej kolumnie.
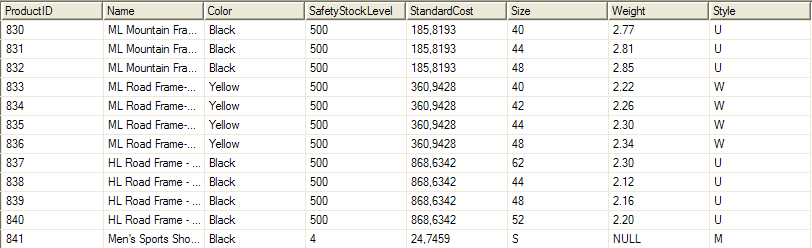
Produkty
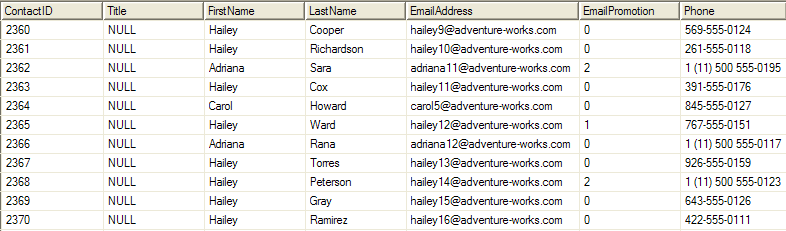
Kontakty
Pracownicy
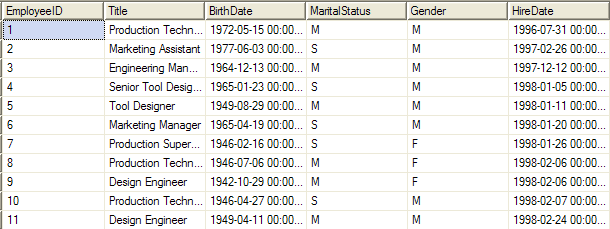
Powyższe zdjęcie pokazuje tabelę z danymi personalnymi osób zatrudnionych lub będących klientami firmy Adventure Works. Kolumny przedstawiają więc informacje o imieniu, nazwisku emailu lub innych danych dotyczących każdej z osób. Wiersze zaś są kolejnymi wpisami odzwierciedlającymi te osoby.
Alternatywną nazwą tabeli jest słowo encja lub relacja. Pierwsze z nich określa jakąś dziedzinę, zbiór danych, który definiuje obiekt. Drugie (relacja) zostało trochę wypaczone przez pierwszą wersję Access, która pojawiła się na polskim rynku, gdzie niefortunnie relacją nazwano asocjacje (połączenie pomiędzy tabelami). Jednakże w środowisku naukowym popularnie stosowane są wszystkie trzy określenia: tabela, relacja i encja.
| Terminologia |
|---|
| Tabela / Relacja / Encja |
| Kolumna / Atrybut |
| Wiersz / Rekord |
W praktyce tabele opisujemy poprzez nazwę kolumn. Na pierwszy rzut oka daje nam to dostateczną ilość informacji o tabeli.
|
Contact (kontakt) |
ContactID, Title, FirstName, LastName, EmailAddress, Phone |
|
Product (towar,product) |
ProductID, Name, Color, Size, Weight, Class, Style |
|
Employee (pracownik) |
EmployeeID, Title, BirthDate, MaritalStatus, Gender, HireDate |
Tabele charakteryzują się sześcioma podstawowymi cechami.
- Autonomiczność wartości
- Kolumny są tego samego typu
- Wiersze są unikalne
- Kolejność ustawienia kolumn jest dowolna
- Kolejność ustawienia wierszy jest dowolna
- Każda z kolumn musi mieć unikalną nazwę
Autonomiczność wartości
Własność ta nakłada ograniczenie na dane wpisywane do pola (skrzyżowanie kolumny i wiersza). Przykładowo: jeśli mamy kolumnę z miastami, to do pojedynczej komórki nie będziemy wpisywać danych w następujący sposób:
|
City |
|---|
|
Szczecin Warszawa Gdańsk |
|
Kraków |
|
Gorzów Wielkopolski |
tylko
|
City |
|---|
|
Szczecin |
|
Kraków |
|
Warszawa |
|
Gdańsk |
|
Gorzów Wielkopolski |
O tej własności szerzej sobie powiemy przy omawianiu zagadnienia związanego z normalizacją relacyjnej bazy danych.
Kolumny są tego samego typu
Oznacza to, że wartośći w danej kolumnie są takiego samego typu. Jeśli kolumna nazywa się BirthDate, musimy mieć pewność, iż wszystkie wartości znajdujące się w tej kolumnie są datami. Mechanizm bazy danych uniemożliwi wpisanie do danej kolumny wartości, która nie mogłaby zostać przekonwertowana do daty. Taka sama sytuacja jest również z polem odpowiedzialnym za stan produktów na magazynie. Przypuśćmy, że w bazie mamy produkty i za opisanie ich liczności odpowiada kolumna Count. Naturalnie spodziewamy się, że liczba ta będzie liczbą całkowitą dodatnią. W tej sytuacji mechanizm serwera bazy danych powinien nie dopuścić do wpisania w tą kolumnę przykładowo wartości tekstowej „osiem”.
Zarówno programiści jak i użytkownicy mogą być pewni typu danych jak jest składowany w danej kolumnie. Umożliwia to sprawdzenie poprawności wpisywania danych za pomocą różnych interfejsów użytkownika.
Unikalność wierszy
Własność ta zapewnia, że w bazie danych nie ma dwóch identycznych wierszy. Aby dodać rekord, musi istnieć w nim przynajmniej jedna kolumna, w której wartości dla poszczególnych wierszy są różne. Aby spełnić to ograniczenie został stworzony mechanizm kluczy, który będzie omówiony w następnym artykule.
Dzięki tej własności mamy zagwarantowaną unikalność wierszy, dzięki czemu każdy rekord może być jednoznacznie zidentyfikowany za pomocą klucza głównego.
Kolejność ustawienia kolumn jest dowolna
Ta własność mówi o tym, że kolejność kolumn w tabeli nie wpływa na
przechowywane w niej dane. Kolumny mogą więc być wstawiane i pobierane w
przypadkowej kolejności i nie będzie miało to najmniejszego znaczenia dla
danych przechowywanych w bazie. Taka organizacja danych sprawia, że użytkownicy
współdzielący dane nie muszą zwracać w tak dużym stopniu uwagi na sposób strukturę.
Dodatkowo umożliwia zmianę fizycznej struktury przechowywania danych bez
żadnego wpływu na strukturę logiczną tabeli.
Kolejność ustawienia wierszy jest dowolna
Własność ta jest analogiczna do tej związanej z kolumnami. Głównym profitem, który z niej wynika, jest możliwość pobierania rekordów w dowolnym porządku. Nie musimy też dodatkowo zapewniać mechanizmów związanych z odpowiednim ustawieniem wierszy.
Każda z kolumn musi mieć unikalną nazwę
Każda z kolumn musi mieć unikalną nazwę, ponieważ nazwa kolumny jest jedyną prostą i intuicyjną możliwością zapewnienia unikalności w tabeli (jeśli kolejność nie ma znaczenia). Unikalność jednak dotyczy wyłącznie tabeli, a nie całej bazy danych.
Podsumowanie
Koncepcja relacyjnych baz danych znacząco ewoluowała od zdefiniowania
koncepcji. Z prostej i dość luźnej teorii stała się ściśle określonym i
rygorystycznie opisanym kanonem zasad.
Sama struktura bazy opiera się na trzech podstawowych pojęciach: tabelach,
kolumnach i wierszach oraz ograniczeniach, wymuszając logiczny schemat i
niepowtarzalność odpowiednich kolumn i wierszy.
